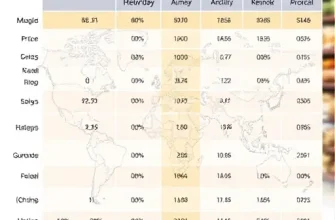
Современная экономика локальных товаров во многом зависит от точности прогнозирования спроса на рынке, где расстояние, логистика и скорость доставки играют ключевую роль. В условиях курьерских сетей с большим количеством маршрутов поведение потребителей может быть непредсельно сложным: спрос растет не только в связи с сезонными колебаниями, но и из-за паттернов перемещений посылок, задержек, функционирования пунктов выдачи и изменений в географии доставки. Настоящая статья посвящена тому, как прогнозировать спрос на локальные товары через анализ паттернов торговых маршрутов курьерской сети на основе искусственного интеллекта. Мы рассмотрим методологию, инструменты обработки данных, алгоритмы прогнозирования и практические шаги внедрения в бизнес-процессы.
- 1. Зачем анализировать паттерны торговых маршрутов курьерской сети для локальных товаров
- 2. Архитектура данных и источники информации
- 3. Предобработка данных и выделение признаков
- 4. Выбор моделей искусственного интеллекта
- 5. Моделирование и обучение: этапы
- 6. Методы оценки эффективности и контроль качества
- 7. Интеграция прогноза в операционные процессы
- 8. Архитектура внедрения: практические рекомендации
- 9. Роли и компетенции в команде
- 10. Риски и способы их минимизации
- 11. Этические и юридические аспекты
- 12. Пример практического кейса
- 13. Технологический стек и инструменты
- 14. Перспективы и дальнейшее развитие
- Заключение
- Как именно используются паттерны торговых маршрутов курьерской сети для прогнозирования спроса на локальные товары?
- Какие данные считаются ключевыми и как их обрабатывать для надежности прогноза?
- Какие практические сценарии использования прогноза спроса для локальных товаров?
- Как интегрировать прогноз спроса в существующую курьерскую сеть без значительных затрат?
1. Зачем анализировать паттерны торговых маршрутов курьерской сети для локальных товаров
Локальные товары традиционно характеризуются ограниченным географическим охватом и быстрым оборотом товаров. Прогнозирование спроса в таком сегменте требует учета множества факторов: доступности товара в точке продаж, времени суток, дня недели, праздничных периодов, погодных условий и логистических ограничений. Анализ паттернов торговых маршрутов курьерской сети позволяет увидеть, как перемещаются товары и информация о нем между узлами сети: складами, пунктами выдачи, магазинами и конечными потребителями. Это дает ценную обратную связь о том, какие районы отличаются высоким спросом и как он меняется во времени.
Преимущества подхода на основе анализа маршрутов включают:
- выявление скрытых корреляций между перемещениями курьеров и спросом на конкретные категории товаров;
- предупреждение о предстоящем росте спроса за счет анализа объемов перевозок по маршрутам, которые обслуживают районы с высоким потенциалом роста;
- оптимизацию ассортимента и оперативное перераспределение товарных запасов между складами и точками выдачи;
- снижение задержек и повышение удовлетворенности клиентов за счет точной синхронизации поставок и доставки.
2. Архитектура данных и источники информации
Эффективный прогноз требует интеграции разнотипной информации. Основные источники включают данные курьерской сети, transactional данные, данные о клиентах и внешние показатели. Ниже приведена типовая архитектура данных:
- логистические данные: маршруты курьеров, время поездок, задержки, использованные транспортные средства, доступность пунктов выдачи;
- товарно-логистические данные: складские запасы, движение по SKU, скорость оборачиваемости, сроки годности;
- покупательские данные: география клиентов, частота покупок, предпочтения по товарам, каналы продаж (онлайн, офлайн);
- событийные данные: акции, скидки, маркетинговые кампании, погодные условия, праздники;
- внешние данные: данные о демографии, экономическая конъюнктура региона, транспортная инфраструктура.
Все данные должны быть структурированы и нормализованы. Важной практикой является создание единого идентификатора локации (геокод, идентификатор района) и временного разреза (час, день, неделя, месяц). Это позволяет строить последовательные временные ряды и сопоставлять изменения в маршрутах с изменениями спроса на товары.
3. Предобработка данных и выделение признаков
Перед моделированием необходимо провести тщательную предобработку данных и построение признаков, которые смогут отражать влияние маршрутов на спрос. Основные шаги включают:
- очистка и консолидация данных: устранение пропусков, привязка данных к единым геокомпонентам, привязка событий к единому временному масштабу;
- географическое агрегацирование: разбиение на зоны (районы, СНИПы, торговые площади), расчёт агрегаций по каждому маршруту;
- временные признаки: день недели, праздник, сезонность, лаговые значения спроса (1–7 дней назад, 2 недели назад и т.д.);
- маршрутные признаки: частота использования конкретных маршрутов, среднее время доставки, вариативность задержек, сезонная активность маршрутов;
- логистические признаки: уровень запасов на складах, скорость пополнения запасов, время простоя точек выдачи;
- поведенческие признаки: конверсия посещений точек выдачи в продажи, средний чек по зоне, влияние акций;
- маркеры внешних факторов: погодные условия, новости о транспортной доступности, статистика спроса по аналогичным районам.
Эти признаки позволяют моделям учитывать причинно-следственные связи между маршрутом курьерской сети и спросом. Важно помнить о многомерности данных и необходимости снижения размерности без потери информативности, чтобы избежать переобучения.
4. Выбор моделей искусственного интеллекта
Для прогнозирования спроса на локальные товары на основе паттернов маршрутов можно применить сочетание классических статистических методов и современных моделей глубокого обучения. Ниже представлен разрез по классам моделей и их применению.
Классические методы:
- ARIMA/ARIMAX: базовый подход к моделированию временных рядов с учетом внешних регрессоров (маршруты, акции);
- Prophet: удобен для сезонности и праздников, способен работать с пропущенными данными и сложными сезонными паттернами;
- Градиентные boosting-методы (XGBoost, LightGBM): хорошие результаты при табличных данных, могут учитывать множество признаков и нелинейности;
- VAR/VARMAX: для многомерного прогнозирования, когда влияние одной переменной на другую носит временной характер.
Модели на основе машинного обучения и глубокого обучения:
- RNN/LSTM/GRU: хорошо работают с последовательными данными и способны учитывать долгосрочные зависимости;
- Transformer-архитектуры: эффективны при большом объеме временных рядов и сложных зависимостях между маршрутами и спросом;
- Graph Neural Networks (GNN): особенно полезны, если представить курьерскую сеть как граф, где узлы — это локации, а рёбра — маршруты; могут учитывать структурные связи между локациями;
- Hybrid-архитектуры: сочетание графовых слоёв для моделирования маршрутов и временных слоёв для динамики спроса.
Выбор модели зависит от целей, доступности данных и вычислительных ресурсов. В реальных задачах часто применяют гибридный подход: сначала строят базовую модель на XGBoost или Prophet, затем дополняют её графовой моделью и последовательно объединяют предсказания через стадию ансамблей.
5. Моделирование и обучение: этапы
Этапы моделирования включают формализацию задачи, настройку гиперпараметров и валидацию. Ниже приведён пошаговый алгоритм:
- формулировка задачи: прогноз спроса на конкретный SKU или группу SKU на определённой территории на заданный временной горизонт;
- разделение данных на обучающую, валидационную и тестовую выборки, учитывая временную последовательность (например, последовательно скользящее окно для временных рядов);
- построение базового набора признаков и оценка метрик точности (MAE, RMSE, MAPE) для начального уровня;
- постепенное добавление признаков, связанных с маршрутами, и оценка их вклада в качество прогноза (feature importance, SHAP-аналитика);
- подбор и настройка модели: выбор архитектуры, регуляризация, лямбда-коэффициенты, коэффициенты штрафа за переобучение;
- кросс-валидация во временном разрезе и тестирование на удерживаемых сегментах территории;
- инструменты развертывания и мониторинга: создание пайплайна обновления прогноза, автоматическое обновление данных и уведомления.
Особое внимание требуется уделять качеству временных меток и синхронизации данных по маршрутам и спросу. Некачественные привязки к времени приводят к искажениям временных зависимостей и ухудшают точность прогноза.
6. Методы оценки эффективности и контроль качества
Эффективность моделей следует оценивать через несколько метрик, которые подбираются под задачу доставки и меру ошибок.
- MAE (средняя абсолютная ошибка) и RMSE (корень из среднеквадратичной ошибки) — для общей точности;
- MAPE (средний относительный процент ошибки) — полезна для сравнений между сегментами с разной шкалой спроса;
- MAPE по сегментам маршрутов: позволяет оценить точность прогноза в зонах с высокой активностью;
- временные показатели: уменьшение задержек доставки, сокращение времени простоя пунктов выдачи;
- показатель обслуживания клиентов: доля точек, у которых прогнозируемый спрос выдаёт нужный товар вовремя;
- эффект на выручку: анализ экономической эффективности внедрения прогностической системы.
Важно проводить регрессионный тест на устойчивость модели к сезонности и новым районным паттернам, чтобы убедиться в надёжности на периодах изменений в структуре маршрутов.
7. Интеграция прогноза в операционные процессы
Прогноз спроса должен переходить из нарезки в actionable insights для операционных команд. Ниже приводятся ключевые направления интеграции:
- управление запасами: настройка уровней reorder point и safety stock по зонам на основе прогнозов, распределение запасов между складами и точками выдачи;
- распределение маршрутов: перераспределение курьеров и оптимизация маршрутов с учётом прогнозируемого спроса в конкретных районах;
- планирование спроса на промо-мероприятия: прогнозирование эффекта акций и специальных предложений по регионам;
- маркетинговые решения: таргетинг на определённые районы на основе прогноза спроса и поведения клиентов;
- кросс-функциональные процессы: связь прогнозных данных с ERP и системами управления запасами для автоматизации.
Важно обеспечить прозрачность моделей для бизнеса: какие признаки влияют на прогноз, как изменяются параметры модели, как часто обновляются данные и какие допущения сделаны.
8. Архитектура внедрения: практические рекомендации
Ниже представлены рекомендации по реальному внедрению системы прогнозирования спроса на основе анализа маршрутов:
- начать с пилотного региона: выбрать один регион с устойчивыми данными и хорошей доступностью торговых маршрутов;
- создать единый репозиторий данных: централизованное хранение маршрутов, запасов, продаж и внешних факторов;
- строить модульные пайплайны: данные -> предобработка -> фичи -> модель -> прогноз -> интеграция в OPS;
- использовать графовые представления маршрутов: графовые фичи дают дополнительную глубину для моделей;
- регулярно обновлять данные и версии моделей: регламенты обновления и мониторинга точности прогноза;
- обеспечить безопасность и соответствие требованиям: защита персональных данных и соответствие регуляторным нормам.
9. Роли и компетенции в команде
Для успешного внедрения необходимы междисциплинарные команды. Основные роли:
- данные-инженеры: сбор, очистка, интеграция данных; построение и поддержка инфраструктуры;
- аналитики данных: исследование паттернов, построение признаков, валидация моделей;
- специалисты по ML: разработка архитектуры моделей, настройка гиперпараметров, мониторинг производительности;
- операционные менеджеры: связь прогноза с запасами, логистикой, планированием маршрутов;
- продуктовые менеджеры: определение требований, KPI, управление бэклогом функций;
- эксперты по данным клиента и комплаенсу: обеспечение приватности, безопасности данных и соответствия требованиям.
10. Риски и способы их минимизации
Любая система прогноза приносит риски, которые требуют внимания:
- неполные данные: риск искажений; решение — внедрить резервные источники данных и методы обработки пропусков;
- переобучение и старение признаков: решение — настройка периодов обновления и контроль качества;
- перегруженность модели признаками: решение — регуляризация и упрощение архитектуры;
- инфляционные и сезонные искажения: решение — использование устойчивых метрик и скользящих окон;
- изменение маршрутов из-за внешних факторов: решение — адаптивные алгоритмы, онлайн-обучение и мониторинг изменений.
11. Этические и юридические аспекты
При работе с данными о клиентах и маршрутах следует учитывать вопросы приватности и безопасности. Необходимо соблюдать требования по защите персональных данных, минимизации сборов данных и прозрачности использования данных клиентами. Также стоит учитывать антимонопольные нормы и правила конкуренции при использовании прогнозов для маркетинга и распределения ресурсов.
12. Пример практического кейса
Рассмотрим упрощённый кейс: сеть локальных магазинов в городе X применяет анализ маршрутов курьеров для прогнозирования спроса на фруктовые наборы в летний период. Руководство решило использовать модель на основе XGBoost с графовыми признаками маршрутов. В результате:
- точность прогноза по MAE снизилась на 15% по сравнению с базовой моделью без маршрутов;
- снижены задержки на доставке в районы, где прогноз показывал высокий спрос;
- оптимизировано распределение запасов между складами: часть запасов перенесли в ближайшие к районам с высоким спросом точки выдачи;
- увеличено общее удовлетворение клиентов за счёт более точной подгонки ассортимента под региональные предпочтения.
13. Технологический стек и инструменты
Ниже приведён ориентировочный набор инструментов для реализации проекта:
- обработку данных: Python, Pandas, PySpark;
- база данных: PostgreSQL, TimescaleDB, BigQuery или Spark SQL;
- обучение моделей: Scikit-learn, XGBoost, LightGBM, TensorFlow, PyTorch;
- графовые модели: DGL, PyTorch Geometric, Nebula Graph;
- визуализация и анализ: Power BI, Tableau, Superset;
- оркестрация и пайплайны: Apache Airflow, Luigi;
- облачные решения: AWS/Azure/Google Cloud в зависимости от инфраструктуры;
- мониторинг и A/B тестирование: MLflow, Weights & Biases, Prometheus, Grafana.
14. Перспективы и дальнейшее развитие
С развитием технологий и расширением географии доставки растет потенциал применения более сложных моделей и нейронных сетей. В ближайшей перспективе можно ожидать:
- интеграцию предсказаний с динамическим планированием маршрутов и автоматическим перераспределением курьеров;
- развитие сегментации клиентов для персонализированных предложений и повышения конверсии;
- усиление графовых подходов за счет более точного моделирования сетевых зависимостей между районами и маршрутами;
- использование онлайн-обучения для адаптации к быстро меняющимся условиям рынка.
Заключение
Прогнозирование спроса на локальные товары через анализ паттернов торговых маршрутов курьерской сети на основе искусственного интеллекта — это стратегически важная область для современных ритейлеров и логистических компаний. Такой подход позволяет увидеть связь между перемещением курьеров и динамикой спроса, точно распределять запасы, оптимизировать маршруты и оперативно реагировать на изменения рынка. Ключ к успешной реализации — качественные данные, продуманная предобработка и работа с графовыми и временными зависимостями в рамках гибкой архитектуры, способной адаптироваться к изменениям. Внедрение подобных систем требует междисциплинарной команды, четкой стратегии данных и постоянного мониторинга результатов. При грамотной настройке и управлении данная технология способен приносить ощутимую экономическую выгоду, сокращать издержки и повышать качество обслуживания клиентов.
Как именно используются паттерны торговых маршрутов курьерской сети для прогнозирования спроса на локальные товары?
Система собирает данные о маршрутах курьеров: точки отправления и назначения, время в пути, частоту маршрутов, задержки и сезонные колебания. Эти данные обогащаются внешними источниками (погода, праздники, акции магазинов). Модели на основе искусственного интеллекта анализируют повторяющиеся паттерны в маршрутах, чтобы определить локальные узлы спроса, сезонные пики и вероятности появления спроса в конкретных районах в определённые окна времени. Результаты помогают планировать запасы и маршруты курьеров с учётом будущего спроса, а не только текущей загрузки.
Какие данные считаются ключевыми и как их обрабатывать для надежности прогноза?
Ключевые данные включают: истории заказов по локациям и времени, маршруты курьеров (точки подпунктов, задержки, частота посещений), временные метки (день недели, час суток), цены и акции, погода, события в городе. Обработка включает очистку ошибок, приведение геоданных к единой системе координат, нормализацию по населённости, а также корреляционный анализ. Модели применяют техники временных рядов, графовые нейронные сети для посещаемости локаций и ансамбли для устойчивости к выбросам. Регулярная валидация на отложенной выборке снижает риск переобучения.
Какие практические сценарии использования прогноза спроса для локальных товаров?
— Планирование запасов в магазинах с учётом ожидаемого спроса в ближайшие дни.
— Оптимизация маршрутов курьеров для балансировки нагрузки и сокращения времени доставки в пики спроса.
— Разработка персонализированных акций в районах с высоким прогнозируемым спросом на конкретные товары.
— Своевременная адаптация ассортимента локальных материалов под сезонность и мероприятия в районе.
— Мониторинг эффективности прогноза и оперативная корректировка стратегии.
Как интегрировать прогноз спроса в существующую курьерскую сеть без значительных затрат?
Начните с внедрения модульной аналитики: собрать данные маршрутов и заказов, выбрать минимальный набор переменных и попробовать простые модели (регрессия, Prophet) на временных рядах. Постепенно добавляйте графовые связи между локациями и паттерны маршрутов. Используйте облачный или локальный вычислительный слой с API для обновления прогнозов в ежедневном режиме. Внедрите A/B тестирование для оценки влияния прогноза на запасы и маршрутизацию. Обучение модели на исторических данных и периодическая переобучение позволят снизить затраты и повысить точность.